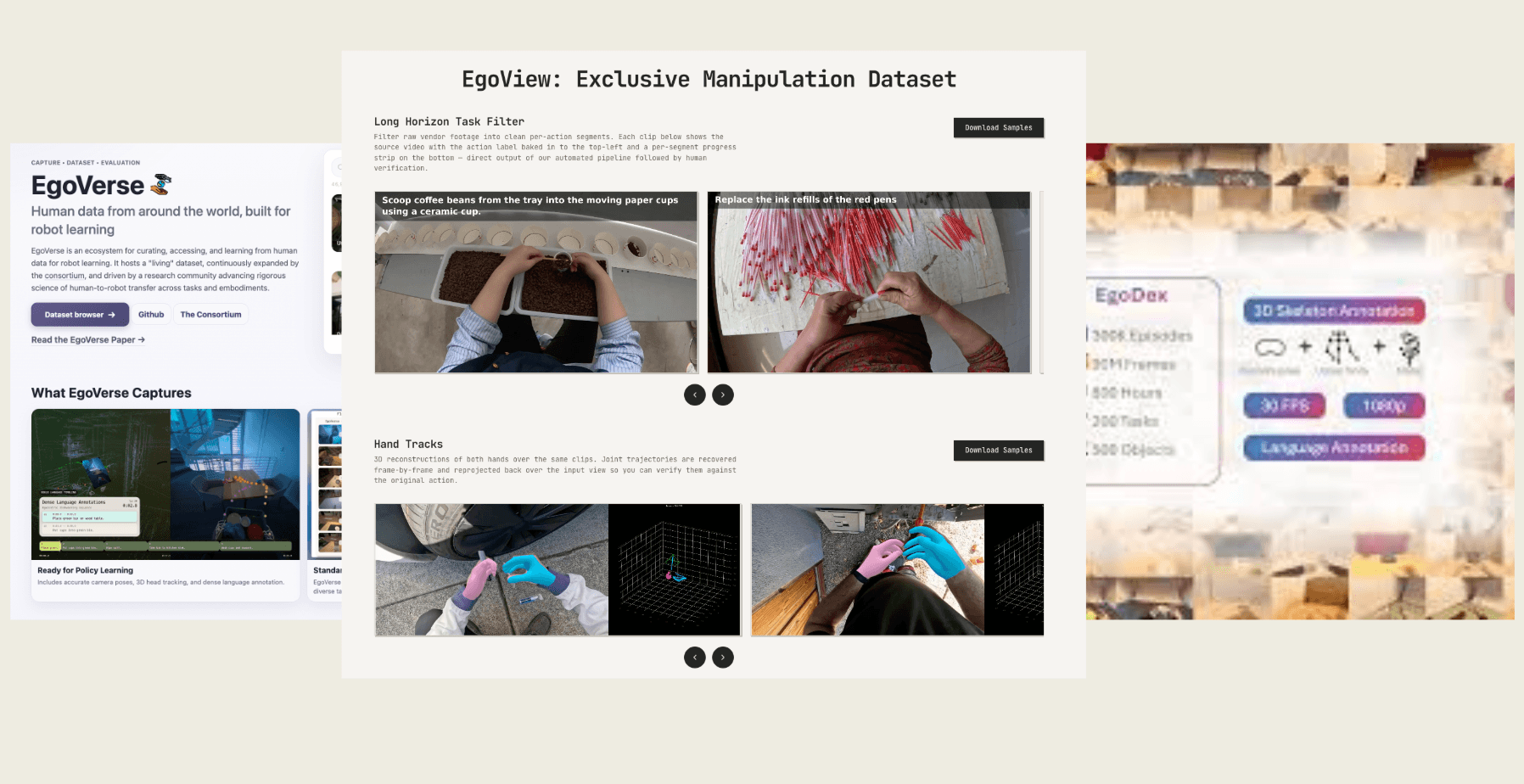
Setting the Standard: What Clean First-Person Video Looks Like
Every frame a model learns from is a vote on what "the world" looks like. Train on noisy, off-axis, or partially occluded first-person footage and your model will fluently reproduce all of it — the blur, the wandering camera, the half-visible hands. Filtering isn't a polish step; it's where the dataset becomes a benchmark.
In this post we share how EgoView compares to two of the most widely cited first-person datasets — EgoVerse and EgoDex — across the eight per-frame signals we use to score every clip that enters our pipeline.
Why a quality standard matters
A first-person dataset has to do two things at once: capture authentic activity, and stay clean enough that a downstream model can actually learn from it. Those goals pull in opposite directions. The more permissive your collection, the more your distribution drifts toward sensor glitches, camera shake during quick head turns, frames where the hand has left the field of view, and motion-blurred frames the model will confidently treat as "normal."
A consistent quality standard gives you a way to keep the authenticity and reject the noise — and, just as importantly, a way to compare across datasets that were each collected under their own assumptions.
How we measure quality
For every frame in every clip, we score eight signals: hand visibility, face presence, image sharpness, camera movement, hand motion, hand framing (vertical and horizontal), and hand count. The signals are aggregated into a single per-clip quality score that gates inclusion in the final dataset. The exact thresholds and weighting are part of EgoView's internal standard.
EgoView vs EgoVerse vs EgoDex — at a glance
| What we measure | EgoView | EgoVerse | EgoDex |
|---|---|---|---|
| Hand visibility | Strong | Strong | Strong |
| Faces in frame (privacy) | 0% | 0% | 0% |
| Image sharpness | Strictest standard — sharpest frames | Comparable | Comparable |
| Camera stability | Tightest bound — least shake | Moderate motion | Higher pixel-level shake |
| Hand motion | Finest, most controlled | Larger, faster motions | Slower, fine motions |
| Hand position (vertical) | Centered | Lower in frame | Centered / upper |
| Hand position (horizontal) | Centered | Skewed right | Centered |
| At least one hand in frame | 100% | ~94% | ~98% |
What stands out
Privacy is a shared baseline. All three datasets pass the no-faces check at 0%. This is now table stakes for first-person data, and we're glad to see the field aligned on it.
Hand visibility is comparable across the board. Detectors find hands with similar confidence on all three datasets — meaning models built on any of them can rely on a clean hand signal when it's present.
The differences show up in stability and framing. EgoVerse leans toward larger, more dynamic motion — bigger gestures, broader physical activity, hands sitting low and to the right of the frame. EgoDex skews toward fine tabletop work, with slower hand motion but more pixel-level camera shake from a wider field of view. EgoView holds a tighter band on every axis: less shake, more controlled hand motion, hands centered both vertically and horizontally, and at least one hand visible in every single frame.
These aren't quality verdicts on EgoVerse or EgoDex — both are valuable resources, and their motion profiles reflect deliberate choices about what kind of activity to capture. EgoView is built for a different point on the spectrum: footage where the framing and motion stay inside the band that downstream models train on most reliably.
Why this matters for what comes next
The gap between "lots of first-person video" and "first-person video a model can actually learn from" is widening as foundation models scale. A consistent, public standard for what "clean" looks like — and a willingness to publish the comparisons — is how the field gets there together.
We'll keep posting comparisons as new first-person datasets land. If you're working on one, we'd love to run yours through the same lens.